
papering Fuzz4All
Fuzz4All: Universal Fuzzing with Large Language Models
摘要
模糊测试在发现各种软件系统中的错误和漏洞方面取得了巨大的成功。接受编程或形式语言作为输入的被测系统(SUTs),例如,编译器,运行时引擎,约束求解器,以及具有可访问api的软件库,因为它们是软件开发的基本构建块而特别重要。然而,这种系统的现有模糊器通常针对一种特定的语言,因此不能轻易地应用于其他语言,甚至是同一语言的其他版本。此外,现有的fuzzers生成的输入通常仅限于输入语言的特定功能,因此很难发现与其他功能或新功能相关的错误。本文提出的Fuzz4All是第一个通用的模糊器,它可以针对许多不同的输入语言和这些语言的许多不同的特征。Fuzz4All背后的关键思想是利用大型语言模型(llm)作为输入生成和突变引擎,这使得该方法能够为任何实际相关的语言生成多样化和现实的输入。为了实现这一潜力,我们提出了一种新的自动提示技术,它创建了非常适合模糊测试的LLM提示,以及一种新的LLM驱动的模糊测试循环,它迭代地更新提示以创建新的模糊测试输入。我们在接受六种不同语言(C、c++、Go、SMT2、Java和Python)作为输入的九个测试系统上评估了Fuzz4All。评估表明,在所有六种语言中,通用模糊测试比现有的特定语言模糊测试实现了更高的覆盖率。此外,Fuzz4All已经在GCC、Clang、Z3、CVC5、OpenJDK和Qiskit量子计算平台等广泛使用的系统中发现了98个bug,其中64个bug已经被开发人员确认为以前未知的。
介绍
模糊测试(fuzz):是一种自动生成可以造成崩溃的输入,从而发现系统的漏洞。
模糊测试可以分为两类:
- 一类是基于变异的模糊测试器,它通过对已有的数据样本进行变异来创建测试用例
- 另一类是基于生成的模糊测试器,它为被测试系统使用的协议或文件格式建模,基于模型生成输入并据此创建测试用例。
上面的两种方法都面临三个挑战:
1.与目标系统和语言的紧密性,对于一个模糊器来说,很难同时适应于多个语言的模糊测试。
2.不能随着时间而更新,特定版本的特定语言fuzzer在后续很难有着高效的测试。
3.无法覆盖大部分输入空间,基于生成的模糊测试因为语法限制,基于变异的模糊测试因为突变限制,都使变异不是十分有效。
于是 提出了Fuzz4ALL 通用模糊器,适用于不同的语言。对于生成和突变来说,使用LLM大语言模型,可以生成高效的变异。对于输入来说,我们需要提供描述的各类文档,还包括示例代码,规范形式等等。因为输入的过于冗长,还需要把输入进行精简提炼成一个有效的输入,作为LLM的初始输入。精简过程不需要用户设计,而是使用LLM的循环提示进行精简,为了避免LLM采用相似的提示,还需要不断更新提示符。
根据实际测试(c,c++,SMT,Go,java,python),fuzz4all比之前的最先进的覆盖率提高了36.8%,检测到98个bug。
背景以及真实工作
大语言模型
基于指令的llm和使用人类反馈强化学习进行的微调的llm被证明能够理解和遵循复杂的指令。利用GPT4合成提示,并根据特定的模糊目标对提示进行评分。
模糊测试
分为两个研究方向,一个是特定系统的模糊测试,一个是通用模糊测试。
这些是传统的模糊测试技术,对于新的模糊测试技术。
基于学习的模糊测试技术,训练神经网络来产生模糊输入,提取初始输入的各种特征来产生一个更好的输入。
基于深度学习的模糊测试技术用于磨合PDF解释器,opencl,c等等。
基于llm来模糊特定的库。
fuzz4all的方法
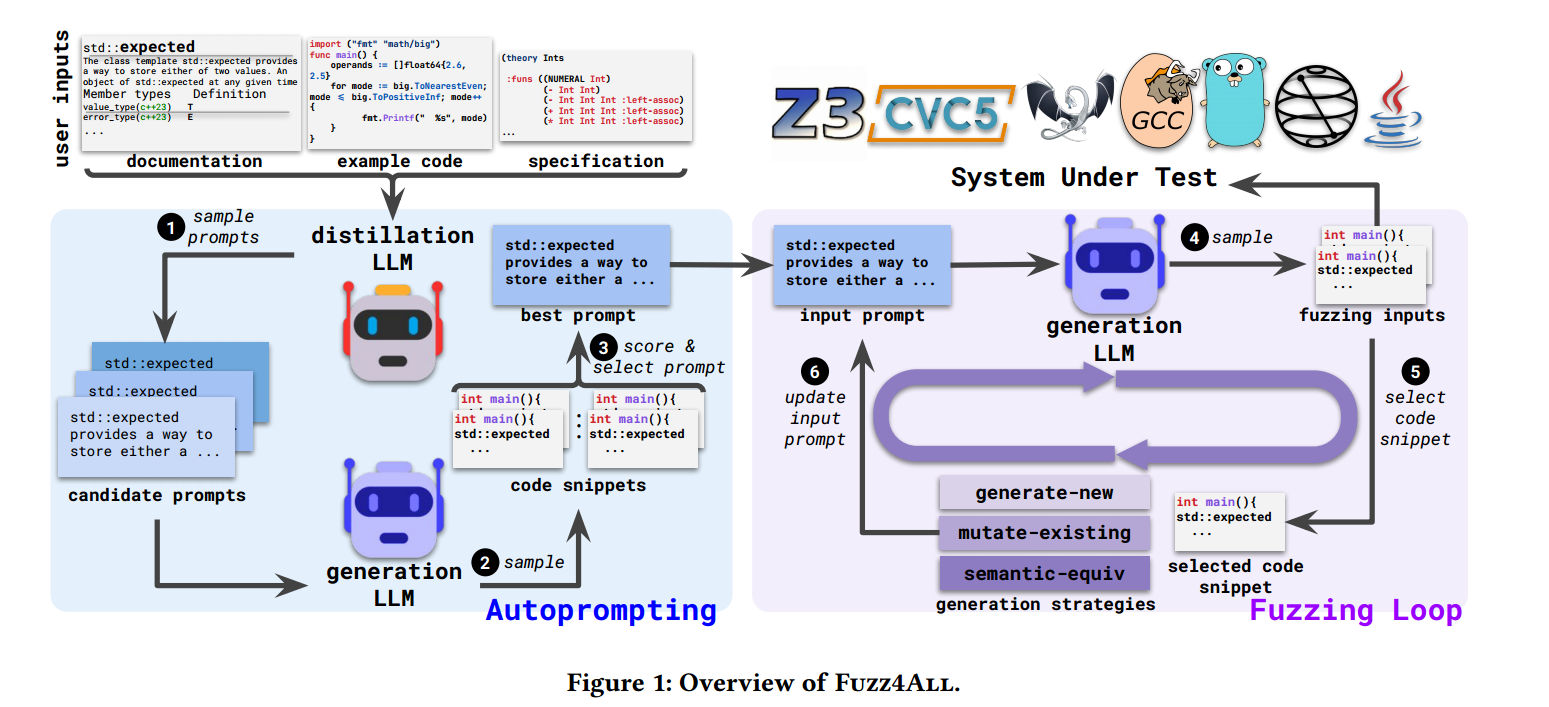
本文记提示词蒸馏的大模型为 MD, 在实验中是 GPT-4
MD (prompt | userInput, APInstruction),利用MD生成numSamples个prompt,再利用自定义评分机制选出最好的 prompt,该 prompt 即为用于生成的提示词。通过低温的首次采样,算法得到一个可信的高置信度的解。然后,算法继续在更高的温度下进行采样,以获得更多样化的提示。与贪婪方法相比,高温采样产生不同的提示,每个提示都可以提供用户输入的唯一摘要。每个生成的提示都被添加到候选列表中。
Fuzzing loop 中使用了生成大模型 MG, 在实验中是StarCoder。
Fuzz4All中种子的保留策略是只保留那些被目标编译器认为是有效的样例。Fuzz4All的变异方法是利用大模型基于不同的生成指令和Automprompting得到的生成提示词提供的背景信息,对于选取的种子做变异。即拼接三者生成提示词,然后进行生成。
实验设计
四个问题
RQ1:Fuzz4All与现有的模糊测试工具相比如何?
RQ2:Fuzz4All在对特定语言特性的模糊测试方面的有效性?
RQ3:不同组件如何影响Fuzz4All的有效性?
RQ4:Fuzz4All找到了哪些现实世界的漏洞?
不足
在精简我们的输入时,使用大语言模型可能造成一些误差,产生虚构或不准确的信息。