
papering LLMs Based Fuzzing
Large Language Models Based Fuzzing Techniques: A Survey
摘要
在软件举足轻重的时代,软件安全与漏洞分析已成为软件开发必不可少的环节。模糊测试作为一种高效的软件测试方法,被广泛应用于各个领域。此外,大型语言模型(llm)的快速发展促进了它们在软件测试领域的应用,并显示出显著的性能。考虑到现有的模糊测试技术并不是完全自动化的,软件漏洞也在不断发展,采用基于大型语言模型生成的模糊测试的趋势越来越大。本调查提供了融合llm和模糊测试的软件测试方法的系统概述。在本文中,通过总结到2024年的最先进的方法,对三个领域的文献进行了统计分析和讨论,包括llm,模糊测试和基于llm生成的模糊测试。我们的调查还调查了LLMs产生的模糊测试技术在未来广泛部署和应用的潜力。
介绍
提出三个问题?
- llm如何用于人工智能和非人工智能相关软件系统的模糊测试?
- 与传统的模糊器相比,基于llms的模糊器有什么优势?
- 基于llms的fuzzer未来的潜力和研究挑战是什么?
调查了14篇论文
分别为:
- Fuzzing-based hard-label black-box attacks against machine learning models [pdf]
- Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models[pdf]
- Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT [pdf]
- ParaFuzz: An Interpretability-Driven Technique for Detecting Poisoned Samples in NLP [pdf]
- Large Language Models for Fuzzing Parsers (Registered Report) [pdf]
- Understanding Large Language Model Based Fuzz Driver Generation [pdf]
- Fuzz4All: Universal Fuzzing with Large Language Models [pdf]
- White-box Compiler Fuzzing Empowered by Large Language Models [pdf]
- AI-Powered Fuzzing: Breaking the Bug Hunting Barrier [Web]
- Large Language Model guided Protocol Fuzzing [pdf]
- Testing the Limits: Unusual Text Inputs Generation for Mobile App Crash Detection with Large Language Model [pdf]
- Smart Fuzzing of 5G Wireless Software Implementation [pdf]
- Augmenting Greybox Fuzzing with Generative AI [pdf]
- CHEMFUZZ: Large Language Models-assisted Fuzzing for Quantum Chemistry Software Bug Detection [pdf]
背景
大型语言模型的强大功能源于将转换器机制合并到模型框架中,这大大提高了其计算能力。
从2019年到2023年,共有75个有影响力的大型语言模型出现。
可以分为:纯解码器语言模型、纯编码器掩码语言模型和编码器-解码器语言模型
纯解码器语言模型:主要用于生成任务,如文本生成和续写。GPT系列
纯编码器掩码语言模型:主要用于理解任务,如文本分类、情感分析和命名实体识别。BERT
编码器-解码器语言模型:主要用于序列到序列任务,如机器翻译和文本摘要。T5,BART
关于llm的模糊测试技术主要来自于纯解码器和编码器-解码器语言模型。
基于LLMs的模糊测试分析
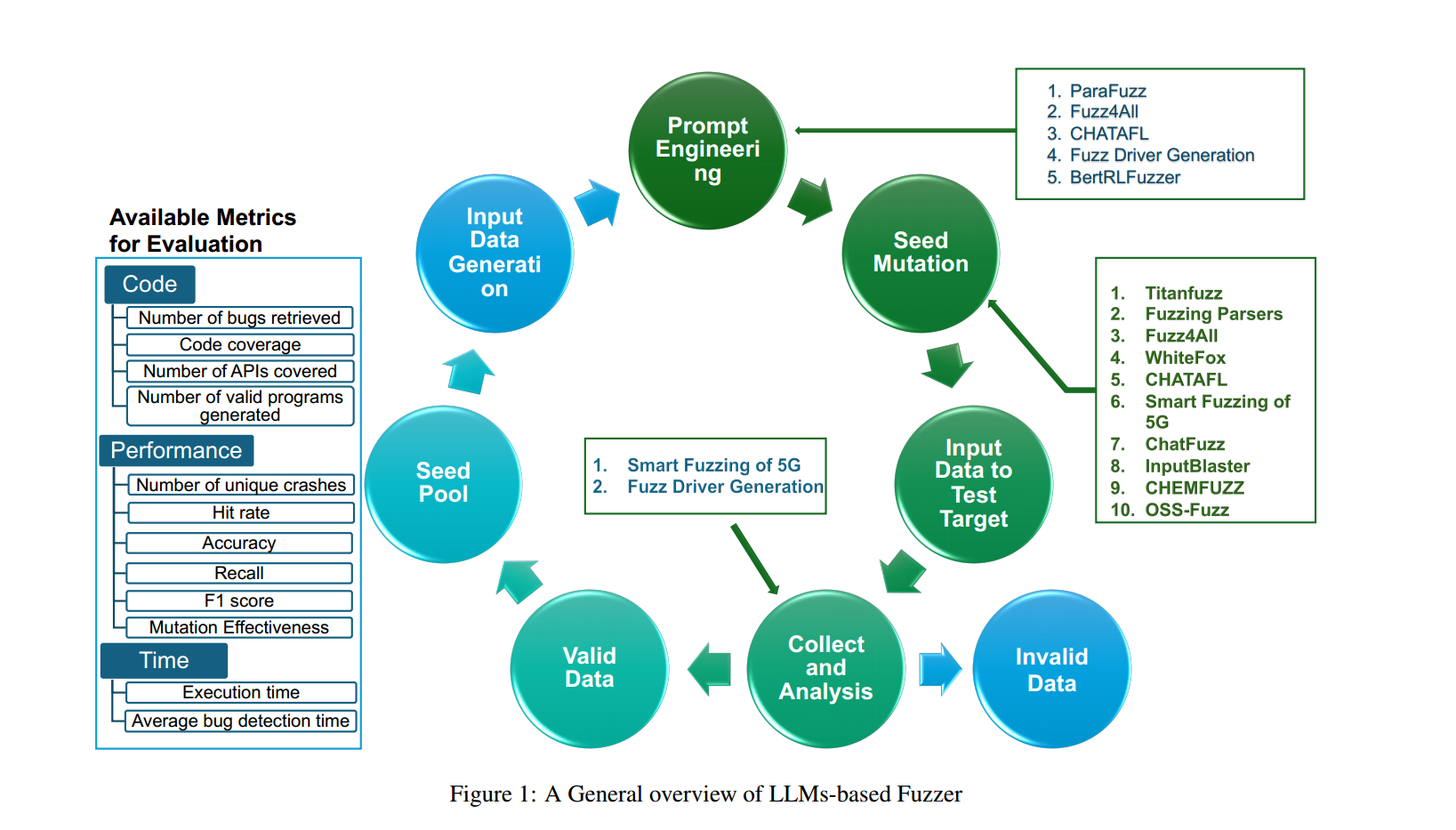
我们发现现有的基于LLMs的fuzzers通常会在提示工程和种子突变中引入LLMs,以提高模糊测试的性能
测试指标
代码:代码覆盖率,检索错误数量
性能:命中率 突变效果 F1
时间:执行速度
基于人工智能
BertRLfuzzer 用来发现web应用程序中的安全漏洞 如SQL注入(SQLi)、跨站脚本(XSS)、跨站请求伪造(CSRF)
TitanFuzz 由大型语言模型生成的深度学习库的技术 主要用在在提示工程和种子突变部分
FuzzGPT 它通过理解历史错误代码来生成更复杂和特定的边缘情况代码片段。
ParaFuzz 解决识别实体词和虚词的同义词和交集
基于非人工智能
Fuzz4all 利用大型语言模型GPT4和StarCoder 作为输入生成和突变引擎
WhiteFox 针对编译器的白盒模糊测试技术 也是建立在两个llm, GPT4和StarCoder上
岑张和他的团队提出了一个基于GPT3.5和GPT4的模糊测试生成器,用于库api的模糊测试 如果加入手动验证 自动化可以达到91%
ChatAFL利用LLM作为网络协议的助手 用来增强灰盒模糊测试
ChemFuzz 是量子化学领域的一种模糊测试软件技术 基于gpt3.5
InputBlaster 基于移动应用的磨合测试 基于生成式大型语言模型、ChatGPT和UIAutomator4的技术。
OSSFuzz 谷歌开发的 与大语言模型结合 有了更好的结果。
在AFL++的基础上 拓展了5g的模糊测试技术。
比传统模糊测试器的优点
高额的代码覆盖率
更高的计算效率
检查错误的能力
更高的自动化更舒服
未来工作
一个是利用过往漏洞进行学习,一个是把大语言模型引入到种子突变和生成的过程中。
无论如何 优秀的模糊测试器应该
1.检测到目标的所有漏洞
2.从多个目标交互中检测代码漏洞
3.识别不同类型的bug
因此,我们预计,在基于llms的模糊器领域的未来发展中,一个更有前途的方法将包括允许模型从历史数据中学习并演变成一个专业的模糊器。llms可以更好地理解软件代码的复杂性和漏洞,从而与综合标准保持一致,而不是改变传统模糊仪的操作过程
然而 关于预训练数据的充分性和质量的挑战是值得注意的(针对上述发展)例如语义上接近重复的内容的存在会增加模型对数据的依赖性。
调用多种多样的API可能需要更多的计算资源和时间。
一个统一的关于llms的模糊测试器的评判标准。
完全自动化