
一次unicorn的学习
@TOC
起因
自己在打MTCTF 2021 100mazes的比赛时,第一次接触到这种大量代码结构相似,却无法使用idapython自动化完成题目,无奈只能手动导出地图,一个一个的解密迷宫,这消耗了大量的时间,最终我在第十关放弃了作答并期待学习像这种结构大量相似的题该如何去做,最后在观看wjh的博客时,发现了他又用unicorn解决了此题目,我参照式的记录了此篇文章,鼓励自己学习更多的关于unicorn的知识。
什么是unicorn
Unicorn是一个轻量级, 多平台, 多架构的CPU模拟器框架,我们可以更好地关注CPU操作, 而忽略机器设备的差异.
缺点:无法模拟整个程序或系统, 也不支持系统调用. 你需要手动映射内存并写入数据进去, 随后你才能从指定地址开始模拟.
用处:使用unicorn可以在比赛中解决大量相似功能模块的题目,完成自动化操作
使用方法
导入模块
1 | from unicorn import * |
寄存器读写
1 | uc.reg_write(UC_X86_REG_RAX, 0x71f3029efd49d41d) |
内存读写
1 | uc.mem_write(CODE, CODE_DATA) |
mem_write:第一个参数传递要写入的地址,第二个参数传递要写入的数据
mem_read:第一个参数传递要读取的地址,第二个参数传递要读取的长度
内存映射
1 | uc.mem_map(ADDRESS, 2 * 1024 * 1024) |
mem_map:第一个参数传递要映射的地址,第二个参数传递要映射的长度(按页对齐)。
如果要执行代码,那么必须需要先映射一块内存地址,然后再通过内存的读写把代码数据写入后执行。
hook
作用:由于并不是程序中的所有代码都可以成功模拟,所以需要对程序的内容进行一些 hook,通过这些 hook 来模拟一些代码的执行(例如 syscall 无法模拟,就需要使用回调的方式模拟 syscall 的执行),也正是通过这些 Hook 操作,使得我们程序的灵活性大大增强,可以实现各种各样的功能。
(hook的内容相对来说比较难理解,但同样的也是有很大的作用)
对每个块的回调
1 | def hook_block(uc, address, size, user_data): |
对每行代码的回调
1 | def hook_code64(uc, address, size, user_data): |
无效内存访问回调
1 | def hook_mem_invalid(uc, access, address, size, value, user_data): |
内存访问回调
1 | def hook_mem_access(uc, access, address, size, value, user_data): |
针对每个指针的回调
1 | def hook_syscall(uc, user_data): |
开始和结束
1 | uc.emu_start(CODE, CODE + 0x3000 - 1) |
emu_start:来执行模拟,第一个参数填写模拟的开始地址,第二个参数填写模拟的结束地址
emu_stop:用来结束模拟
例题:MTCTF2021 100mazes
main
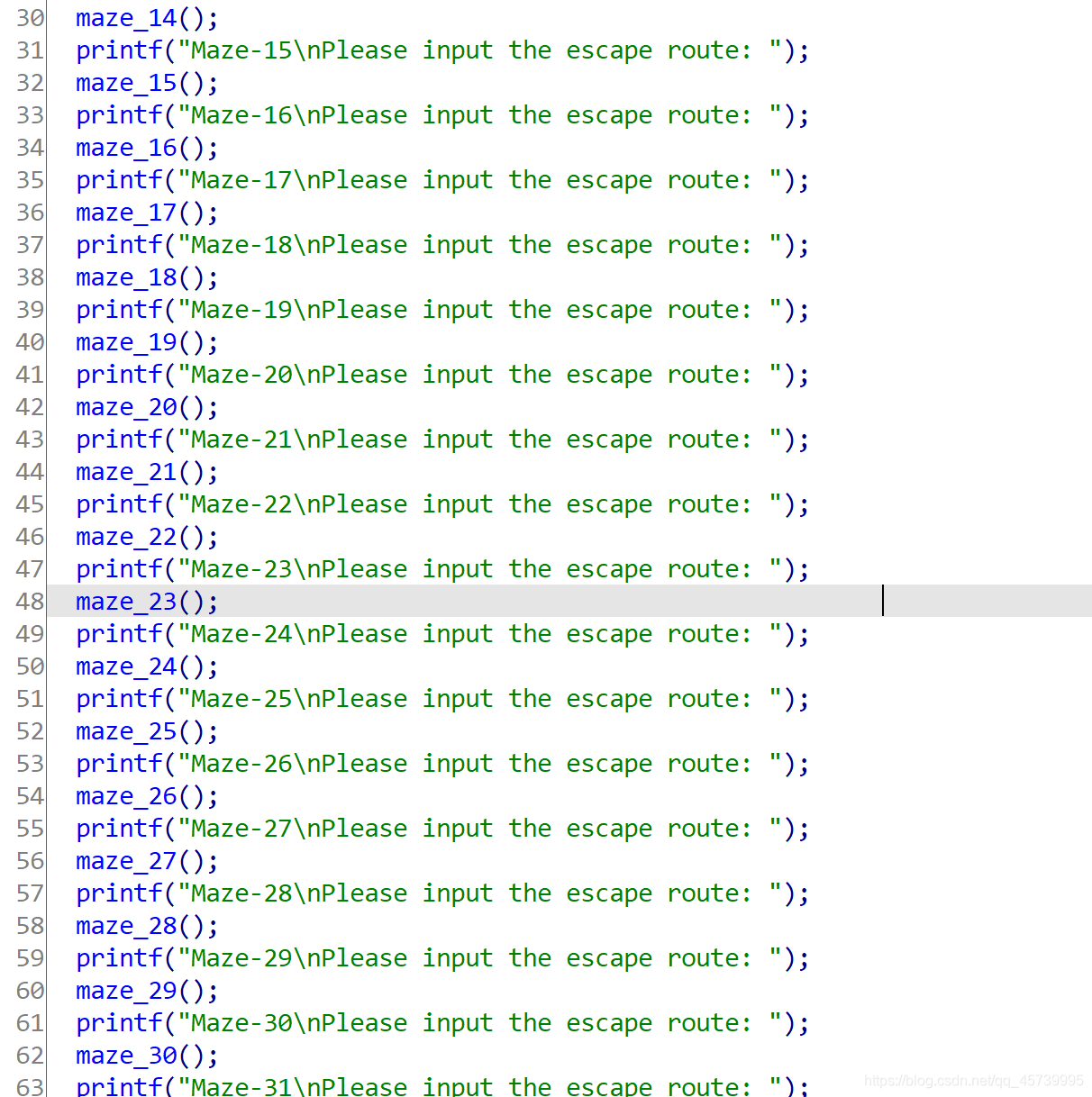
a maze
可以观察到这里在主函数上有一百个迷宫,我们随便打开其中的一个进行分析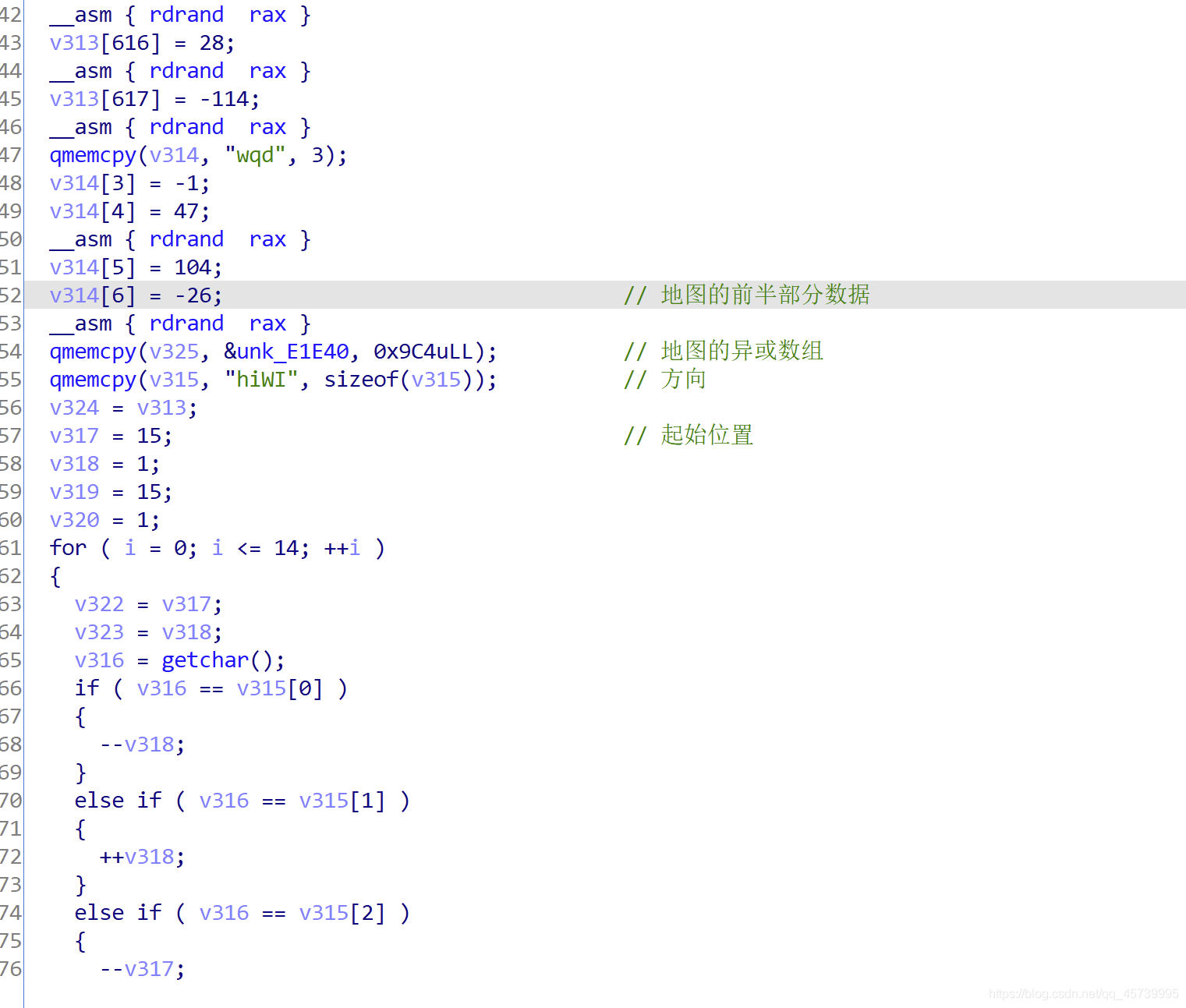

观察到栈上的数据是这样的,我们可以直接根据 rbp 来寻址提取各个数据的内容,然后再进行解密操作 并且注意到这里有一个 getchar 函数,由于我们没有装载 libc,所以这个函数是无法被 unicorn 所模拟的,我们就可以以这里为当前迷宫读取结束的位置,hook 所有执行到这个函数的代码,并且数据进行解析,并且在执行完这个函数后执行 retn 到上一层的函数。
并且注意到这里有一个 getchar 函数,由于我们没有装载 libc,所以这个函数是无法被 unicorn 所模拟的,我们就可以以这里为当前迷宫读取结束的位置,hook 所有执行到这个函数的代码,并且数据进行解析,并且在执行完这个函数后执行 retn 到上一层的函数。
代码
1 | from hashlib import md5 |
可以结合上述的描述来尝试理解一下代码,我这里分析几处比较重要的地方
首先是,程序中除了代码空间还存在栈空间,所以我们除了需要映射代码空间,还需要映射一块足够大的栈空间,并且赋值给 RSP 寄存器适当的位置(最好选择一个中间位置)。
接下来我是用一个 hook 钩子来对每一行指令进行检查(在实际使用的时候都最好先挂上这样的一个钩子便于确认程序在哪里出现了异常),并且为了偷懒,直接在这个钩子中对地址进行判断来做相应的操作。
- 对 rdrand rax 这个指令直接跳过,因为似乎 unicorn 无法正确的识别这个指令,并且这个指令对程序流程并没有实际上的影响,所以这里我直接跳过。

对 printf 函数直接跳过,但是由于 plt@printf 的实现问题,我这里需要手动模拟 retn 操作,这再次体现了 unicorn 的灵活性。
对于遇到 getchar 函数的时候,执行读取迷宫数据操作,读取之后进行 dfs 寻找答案,并组合输出,由于题目要求的是对最后的所有输入取 md5 作为 flag,所以这里还保存了所有的输入。这里我尝试手动模拟了 leave;ret 来返回到主函数
参考链接
http://blog.wjhwjhn.com/archives/288/
https://bbs.pediy.com/thread-224315.htm
https://github.com/unicorn-engine/unicorn/tree/master/bindings/python